在現代IT服務與云計算領域,服務可用性是衡量服務質量的核心指標之一。其中,SLA(Service Level Agreement,服務級別協議)中常見的“4個9”承諾,以及如何通過高可用性(High Availability, HA)架構來確保這一目標,尤其對于數據庫和數據處理服務至關重要。本文旨在解析這些概念,并探討其實踐路徑。
一、SLA服務可用性“4個9”的含義
SLA是服務提供商與客戶之間關于服務性能、可用性等方面的正式協議。服務可用性通常以百分比表示,而“幾個9”則是對該百分比的形象說法。
- 4個9(99.99%):這意味著服務在一年中的計劃停機時間不得超過約52.56分鐘(計算方式:365天 × 24小時 × 60分鐘 × (1 - 0.9999) ≈ 52.56分鐘)。這是一個非常高的可用性標準,常見于金融、電信、核心電商等對連續性要求極嚴苛的業務場景。
更高的標準還有5個9(99.999%,年停機約5.26分鐘)等,但實現成本和復雜度呈指數級增長。4個9通常被認為是商業關鍵系統在成本與可靠性間的一個高效平衡點。
二、如何保證服務的高可用性(HA)
高可用性(HA)是指系統能夠持續提供服務,減少因硬件故障、軟件缺陷、人為操作或自然災害導致的意外停機時間。實現HA并非單一技術,而是一套涵蓋架構設計、運維流程與技術的綜合體系。
1. 核心設計原則
- 消除單點故障(SPOF):系統中的任何組件(服務器、網絡鏈路、電源等)都應具備冗余備份,確保單一組件故障不會導致整體服務中斷。
- 故障自動檢測與切換:當主組件發生故障時,系統應能自動、快速地將流量或任務切換到備用組件,通常要求在秒級或分鐘級內完成。
- 負載均衡:通過將請求分發到多個服務器實例,避免單個實例過載,同時提升整體處理能力和冗余性。
2. 關鍵實現策略與技術
- 冗余架構:
- 服務器集群:如Web服務器集群、應用服務器集群。
- 網絡冗余:多線路接入、交換機堆疊或虛擬化技術。
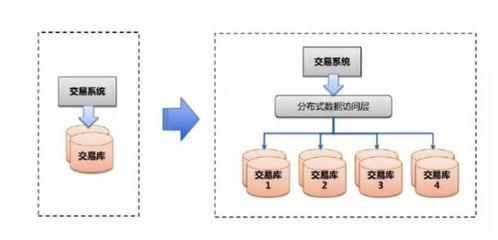
- 數據存儲冗余:這是數據庫高可用的基石。
- 數據庫高可用性方案:
- 主從復制(Master-Slave Replication):主庫處理寫操作,并異步或同步復制數據到一個或多個從庫,從庫處理讀操作。主庫故障時,可將一個從庫提升為主庫(需配合VIP或代理如ProxySQL)。
- 主主復制(Master-Master Replication):兩個數據庫互為主從,均可讀寫,但需謹慎處理數據沖突。
- 數據庫集群:如MySQL Group Replication、Percona XtraDB Cluster(基于Galera),提供多主同步復制,實現更高可用性和數據一致性。
- 使用云數據庫服務:如AWS RDS Multi-AZ部署、Google Cloud SQL高可用版、阿里云RDS高可用版等,它們通常內置了自動故障轉移的HA架構。
- 數據備份與災難恢復(DR):定期全量及增量備份,并結合異地備份(如跨可用區、跨地域)以應對區域性災難。確保RTO(恢復時間目標)和RPO(恢復點目標)符合業務要求。
- 自動化運維與監控:
- 全面監控:對服務器性能、應用狀態、網絡狀況、業務指標進行7×24小時監控,設置智能告警。
- 自動化部署與回滾:使用CI/CD工具鏈,確保新版本發布可快速回滾以減少故障窗口。
- 混沌工程:在可控環境中故意引入故障,以驗證系統的彈性和恢復能力。
三、對數據處理服務的特別考量
對于數據處理服務(如ETL流水線、實時流處理、大數據分析平臺),高可用性挑戰可能更復雜:
- 狀態管理:對于有狀態的處理任務(如Spark Streaming、Flink作業),需要將狀態信息持久化到高可用的外部存儲(如HDFS、S3、高可用數據庫),并支持從檢查點(Checkpoint)恢復。
- 流水線彈性設計:采用消息隊列(如Kafka、Pulsar)作為緩沖層,解耦生產與消費環節,允許下游處理環節臨時故障而不丟失數據。
- 資源調度與彈性伸縮:在Kubernetes或云原生環境下,利用HPA(水平Pod自動伸縮)和集群自動伸縮組,根據負載動態調整資源,應對流量高峰,并自動替換不健康的Pod或實例。
四、
承諾“4個9”的SLA不僅是服務提供商技術能力的體現,更是對客戶業務連續性的堅實保障。實現這一目標,需要從系統架構的頂層設計開始,深入貫徹高可用性原則,并在數據庫、網絡、應用層和數據處理流程等各個環節采用成熟的冗余、監控與自動化技術。正如技術社區(如CSDN博客上的專家universsky2015等分享的經驗)所不斷探討的,這是一個持續演進、測試和優化的過程,沒有一勞永逸的方案,唯有通過嚴謹的設計與運維,方能在動態變化的環境中確保服務的高可用性。