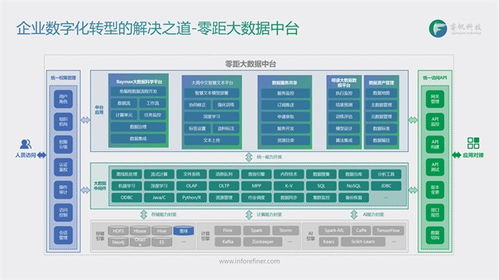
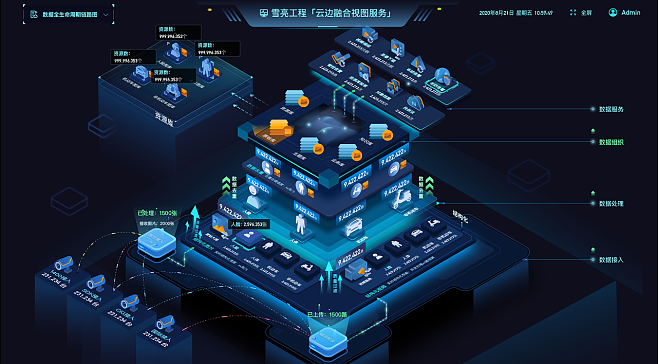
在B站這樣日活用戶過(guò)億的平臺(tái)中,數(shù)據(jù)處理服務(wù)作為大數(shù)據(jù)開發(fā)治理平臺(tái)的核心模塊,承擔(dān)著海量數(shù)據(jù)的高效處理與價(jià)值挖掘任務(wù)。經(jīng)過(guò)多年實(shí)踐與迭代,我們?cè)跀?shù)據(jù)處理服務(wù)的設(shè)計(jì)上積累了一些重要心得。
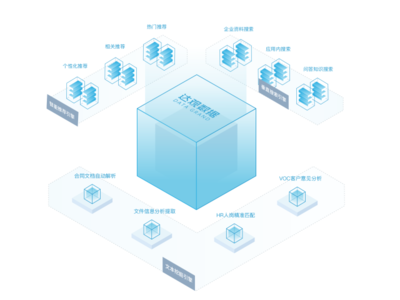
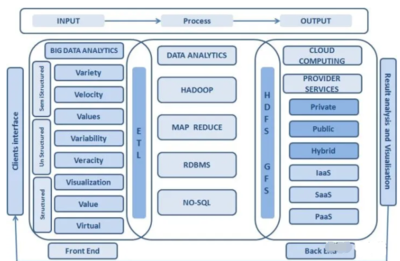
數(shù)據(jù)處理服務(wù)的設(shè)計(jì)需以業(yè)務(wù)場(chǎng)景為導(dǎo)向。B站業(yè)務(wù)場(chǎng)景多樣,涵蓋視頻推薦、彈幕分析、用戶畫像構(gòu)建等多個(gè)維度。為此,我們?cè)O(shè)計(jì)了模塊化的數(shù)據(jù)處理流水線,支持對(duì)不同數(shù)據(jù)源(如日志、數(shù)據(jù)庫(kù)、流數(shù)據(jù))的統(tǒng)一接入,并提供靈活的ETL(提取、轉(zhuǎn)換、加載)工具。通過(guò)預(yù)置常用數(shù)據(jù)處理模板(如去重、聚合、關(guān)聯(lián)),業(yè)務(wù)團(tuán)隊(duì)可快速構(gòu)建數(shù)據(jù)流,無(wú)需重復(fù)開發(fā)。
性能與穩(wěn)定性是數(shù)據(jù)處理服務(wù)的生命線。面對(duì)TB級(jí)甚至PB級(jí)的數(shù)據(jù)量,我們采用了分布式計(jì)算框架(如Spark、Flink)作為底層引擎,并結(jié)合B站特有的數(shù)據(jù)特征進(jìn)行調(diào)優(yōu)。例如,在實(shí)時(shí)數(shù)據(jù)處理場(chǎng)景中,我們優(yōu)化了流處理任務(wù)的資源調(diào)度策略,確保在高并發(fā)下仍能維持毫秒級(jí)延遲。同時(shí),通過(guò)監(jiān)控告警、自動(dòng)容錯(cuò)和重試機(jī)制,保障數(shù)據(jù)處理的可靠運(yùn)行,避免因單點(diǎn)故障導(dǎo)致數(shù)據(jù)丟失或延遲。
第三,易用性與可擴(kuò)展性是提升團(tuán)隊(duì)協(xié)作效率的關(guān)鍵。我們?cè)跀?shù)據(jù)處理服務(wù)中集成了可視化配置界面,用戶可通過(guò)拖拽方式定義數(shù)據(jù)流程,降低技術(shù)門檻。服務(wù)支持插件化擴(kuò)展,允許開發(fā)團(tuán)隊(duì)自定義UDF(用戶定義函數(shù))或集成第三方工具,以適應(yīng)新興業(yè)務(wù)需求。例如,針對(duì)AI模型訓(xùn)練的數(shù)據(jù)預(yù)處理,我們引入了TensorFlow Data Service的集成模塊,簡(jiǎn)化了特征工程流程。
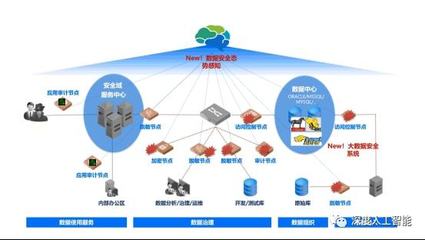
數(shù)據(jù)治理與安全貫穿于數(shù)據(jù)處理全過(guò)程。我們?cè)O(shè)計(jì)了數(shù)據(jù)血緣追蹤功能,記錄每個(gè)數(shù)據(jù)集的來(lái)源、變換和流向,便于問題溯源和影響分析。同時(shí),通過(guò)權(quán)限控制和數(shù)據(jù)脫敏機(jī)制,確保敏感信息(如用戶隱私)在數(shù)據(jù)處理中的合規(guī)性。
B站大數(shù)據(jù)開發(fā)治理平臺(tái)的數(shù)據(jù)處理服務(wù),成功融合了業(yè)務(wù)導(dǎo)向、高性能、易用性和治理安全等要素。未來(lái),我們將繼續(xù)探索智能化數(shù)據(jù)處理(如AutoML集成)和跨云混合部署,以應(yīng)對(duì)更復(fù)雜的業(yè)務(wù)挑戰(zhàn),為B站生態(tài)提供更強(qiáng)大的數(shù)據(jù)支撐。